用python爬取酷狗(网易云)音乐
(此文为小左1120原创,转载请标明出处,如违规请联系作者立刻删除)
此文为python爬虫文章,讲了用python爬取某狗里的歌名并下载(包括vip)后面带exe

2020/8/5
由于本人爬虫经验不足,代码可能会粗糙,有bug,麻烦大佬加个微信QQ一起学吧!代码失效了也给我通知一声(图片如果显示不出来的话请多次刷新,若问题仍存在,请告诉我换源)
微信:aicoder-XZ
QQ:2583188733
老规矩
配置好python
配置好pycharm
再安装依赖的模块:
点这里(感谢大神的文章)
接下来,按下win+R输入cmd-回车!在窗口里输入
1
| pip install requests selenium
|
打开pycharm,
新建项目,(不会的话点这里)
进去后,右键文件夹,
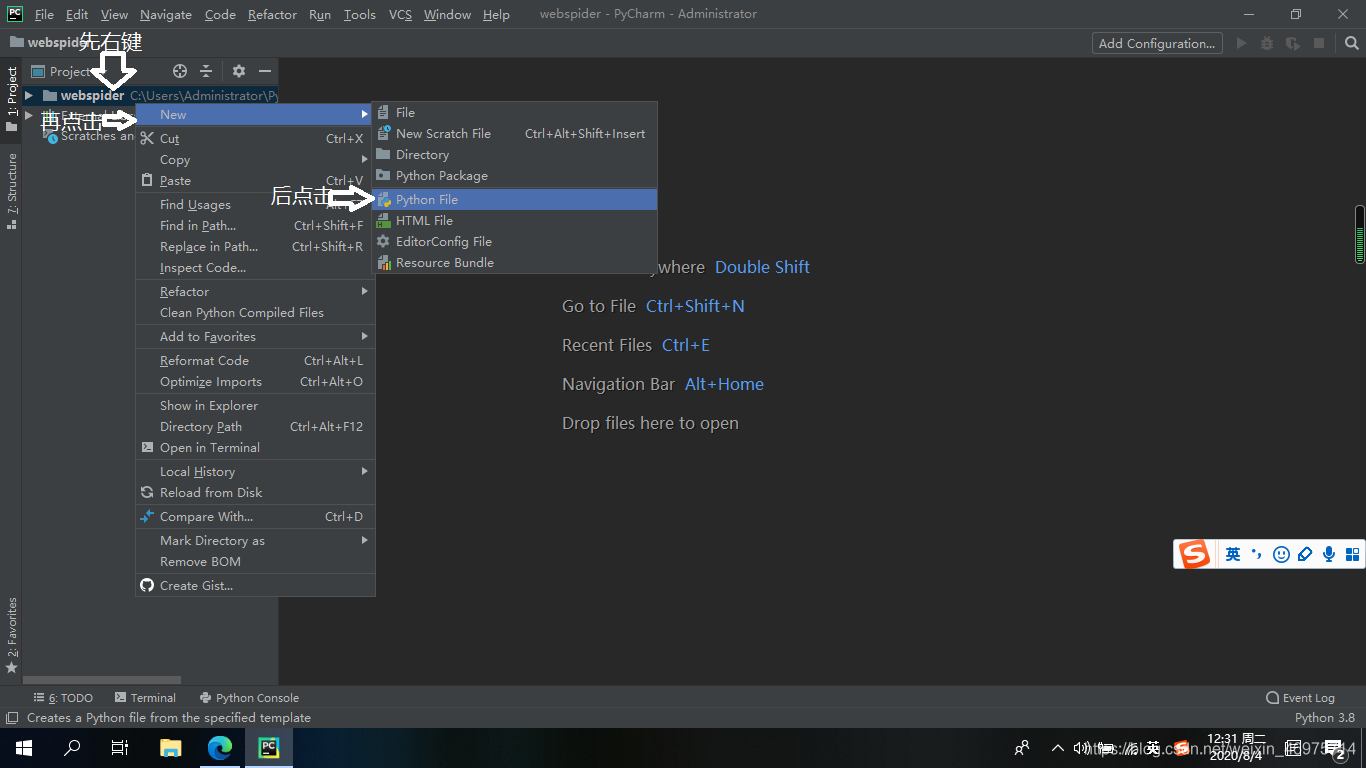
输入个你喜欢的名字,回车!
开始写代码吧!
先打开浏览器
访问某狗音乐下载(不要用ie)

随便搜索搜索看看网址
以《癞蛤蟆》为例
网址是
1
| https://music.liuzhijin.cn/?name=癞蛤蟆&type=kugou
|
所以搜索的格式是
好,咱先爬:
1
2
3
4
5
6
7
| from selenium import webdriver
import time
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
browser = webdriver.Firefox()
browser.get(url)
|
这个网站有一点问题,底下有个载入更多,不能直接全部加载,
没有事的。。
按下F12
在出来的控制台的左上角点这个按钮

点击载入更多
ok,浏览器会定位到这样一条元素,
1
| <div class="aplayer-more">载入更多</div>
|
右击-复制-完整的XPath(火狐是XPath)
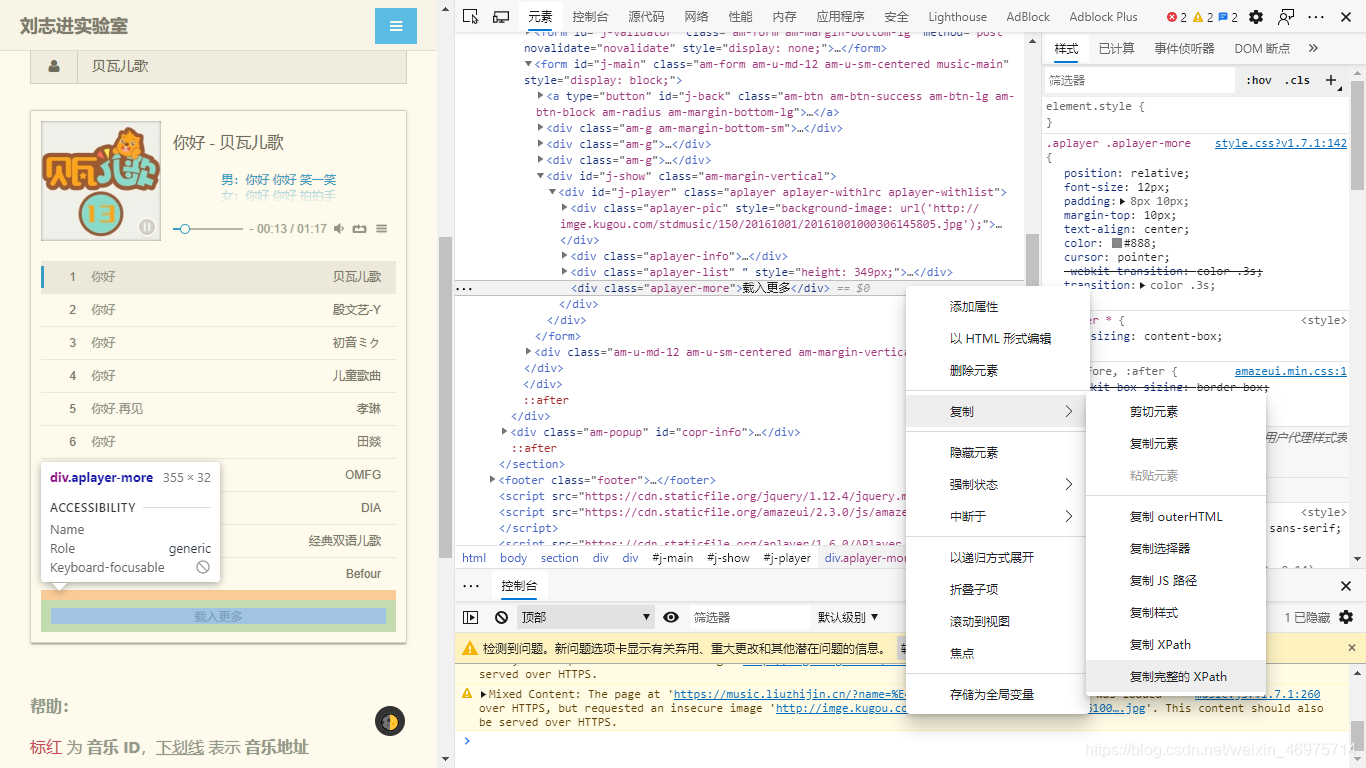
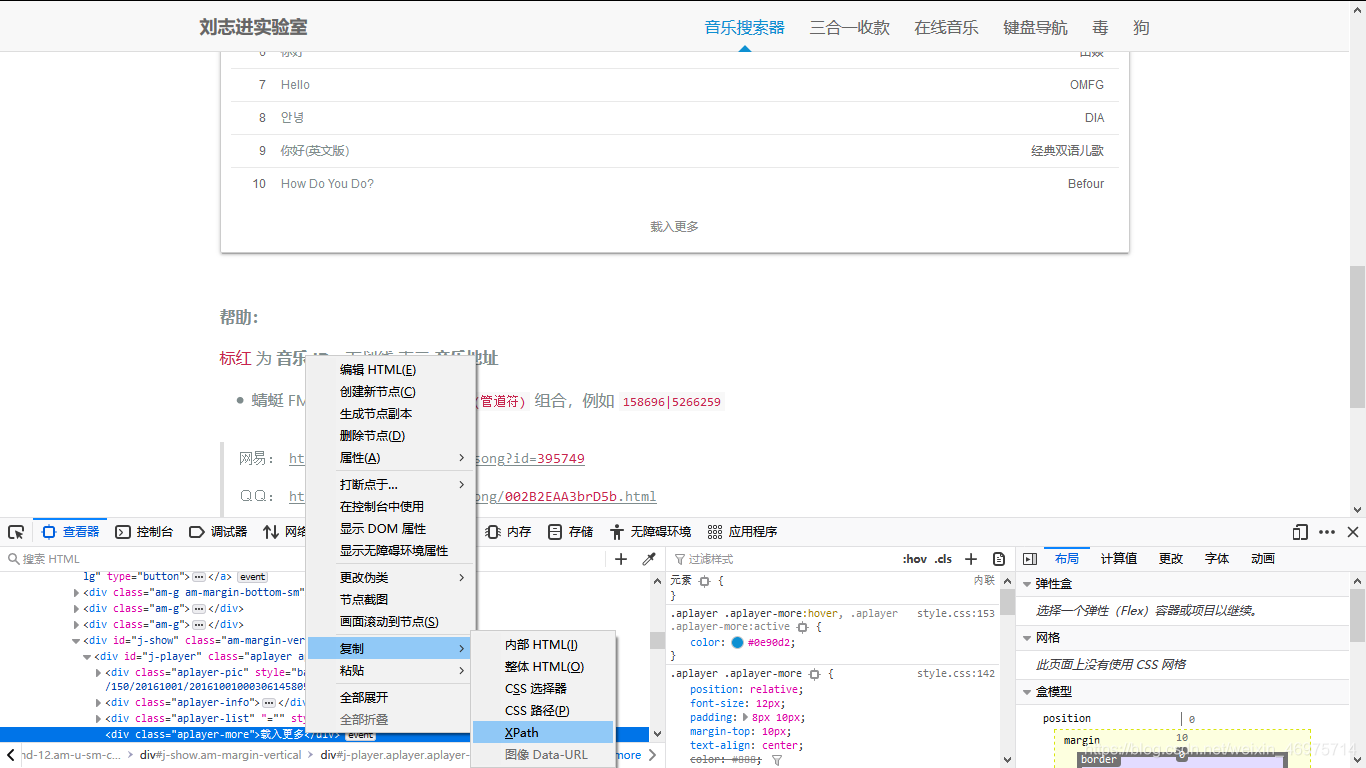
好
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from selenium import webdriver
import time
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
browser = webdriver.Firefox()
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("你的XPath").click()
except:
break
|
我的是/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]
所以就是
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| from selenium import webdriver
import time
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
browser = webdriver.Firefox()
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
|
一切就绪,获取网页源代码
1
| html = browser.page_source
|
控制台上看一看
看到一大堆li
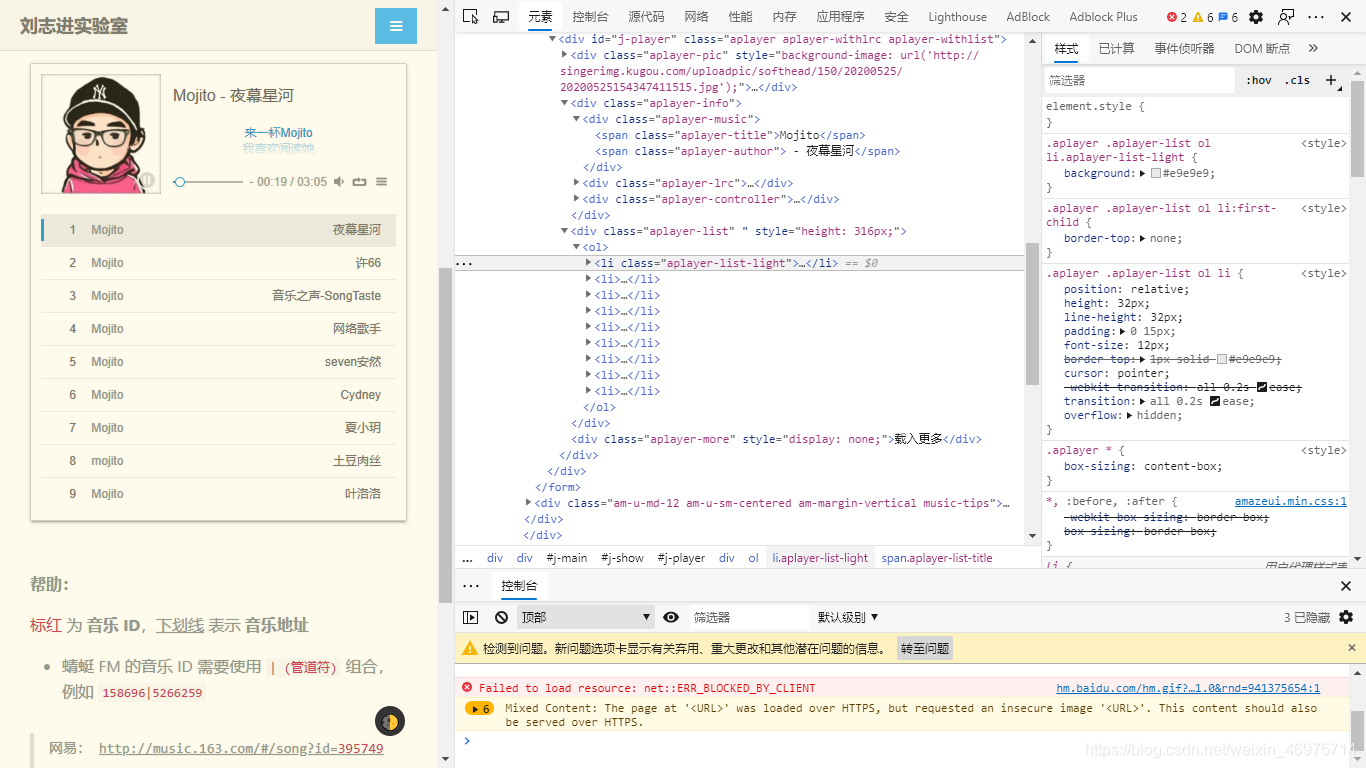
挑一个(我搜索的Mojito)
1
2
3
4
5
6
7
8
9
10
11
12
| <li>
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">2</span>
<span class="aplayer-list-title">Mojito</span>
<span class="aplayer-list-author">许66</span>
</li>
<li>
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">3</span>
<span class="aplayer-list-title">Mojito</span>
<span class="aplayer-list-author">音乐之声-SongTaste</span>
</li>
|
经过阅读知道
1
2
3
4
5
6
| <li>
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">歌曲排名</span>
<span class="aplayer-list-title">歌曲名</span>
<span class="aplayer-list-author">歌手</span>
</li>
|
呵呵呵,我们用正则表达式提取一下,顺便封装成方法

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
from selenium import webdriver
import time,re
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
def geturl(url):
browser = webdriver.Firefox()
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
return browser.page_source
html = geturl(url)
a111 = '''<li class="aplayer-list-light">
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>
'''
a11='''<li>
<span class="aplayer-list-cur" style="background: .*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a='''<li>
<span class="aplayer-list-cur" style="background:.*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a1=re.findall(a111,html)
b1 = re.findall(a11,html)
b2=re.findall(a,html)
data = a1+b1+b2
|
加上选择
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
from selenium import webdriver
import time,re
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
def geturl(url):
browser = webdriver.Firefox()
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
return browser.page_source
html = geturl(url)
a111 = '''<li class="aplayer-list-light">
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>
'''
a11='''<li>
<span class="aplayer-list-cur" style="background: .*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a='''<li>
<span class="aplayer-list-cur" style="background:.*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a1=re.findall(a111,html)
b1 = re.findall(a11,html)
b2=re.findall(a,html)
data = a1+b1+b2
song = 0
for i in data:
print(i)
num = input(">>")
for i in data:
if (str(i[0])==num):
song = i
url = "https://music.liuzhijin.cn/?name=" + song[1]+' - '+song[2] + "&type=kugou"
print(geturl(url))
|
看下载链接的位置的代码是
1
2
3
4
5
| <span class="am-input-group-btn">
<a id="j-src-btn" class="am-btn am-btn-default" target="_blank" href="(.*?)" download="(.*?)">
<i id="j-src-btn-icon" class="am-icon-download"></i>
</a>
</span>
|
我们通过搜索歌曲名 - 歌手来搜索并下载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
from selenium import webdriver
import time,re,requests
name = input(">")
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
def geturl(url):
browser = webdriver.Firefox()
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
return browser.page_source
html = geturl(url)
a111 = '''<li class="aplayer-list-light">
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>
'''
a11='''<li>
<span class="aplayer-list-cur" style="background: .*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a='''<li>
<span class="aplayer-list-cur" style="background:.*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a1=re.findall(a111,html)
b1 = re.findall(a11,html)
b2=re.findall(a,html)
data = a1+b1+b2
song = 0
for i in data:
print(i)
num = input(">>")
for i in data:
if (str(i[0])==num):
song = i
url1 = "https://music.liuzhijin.cn/?name=" + song[1]+' - '+song[2] + "&type=kugou"
a7='''<span class="am-input-group-btn">
<a id="j-src-btn" class="am-btn am-btn-default" target="_blank" href="(.*?)" download="(.*?)">
<i id="j-src-btn-icon" class="am-icon-download"></i>
</a>
</span>
'''
html1=geturl(url1)
a8 = re.findall(a7,html1)
r = requests.get(a8[0][0])
with open(a8[0][1], "wb") as code:
code.write(r.content)
|
接下来是优化环节:
我发现,用这东西乱蹦浏览器,我们使用无头模式,再加一个循环
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
|
from selenium import webdriver
import time,re,requests
while True:
name = input("输入你想下载的歌曲名并按下回车(不输入并按下回车退出):")
if (name==''):
break
else:
url = "https://music.liuzhijin.cn/?name=" + name + "&type=kugou"
def geturl(url):
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
browser = webdriver.Firefox(options=options)
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
temp = browser.page_source
browser.close()
return temp
html = geturl(url)
a111 = '''<li class="aplayer-list-light">
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>
'''
a11='''<li>
<span class="aplayer-list-cur" style="background: .*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a='''<li>
<span class="aplayer-list-cur" style="background:.*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a1=re.findall(a111,html)
b1 = re.findall(a11,html)
b2=re.findall(a,html)
data = a1+b1+b2
song = 0
for i in data:
print(i)
num = input("请输入序号:")
for i in data:
if (str(i[0])==num):
song = i
url1 = "https://music.liuzhijin.cn/?name=" + song[1]+' - '+song[2] + "&type=kugou"
a7='''<span class="am-input-group-btn">
<a id="j-src-btn" class="am-btn am-btn-default" target="_blank" href="(.*?)" download="(.*?)">
<i id="j-src-btn-icon" class="am-icon-download"></i>
</a>
</span>
'''
html1=geturl(url1)
a8 = re.findall(a7,html1)
r = requests.get(a8[0][0])
with open(a8[0][1], "wb") as code:
code.write(r.content)
|
使用示例:
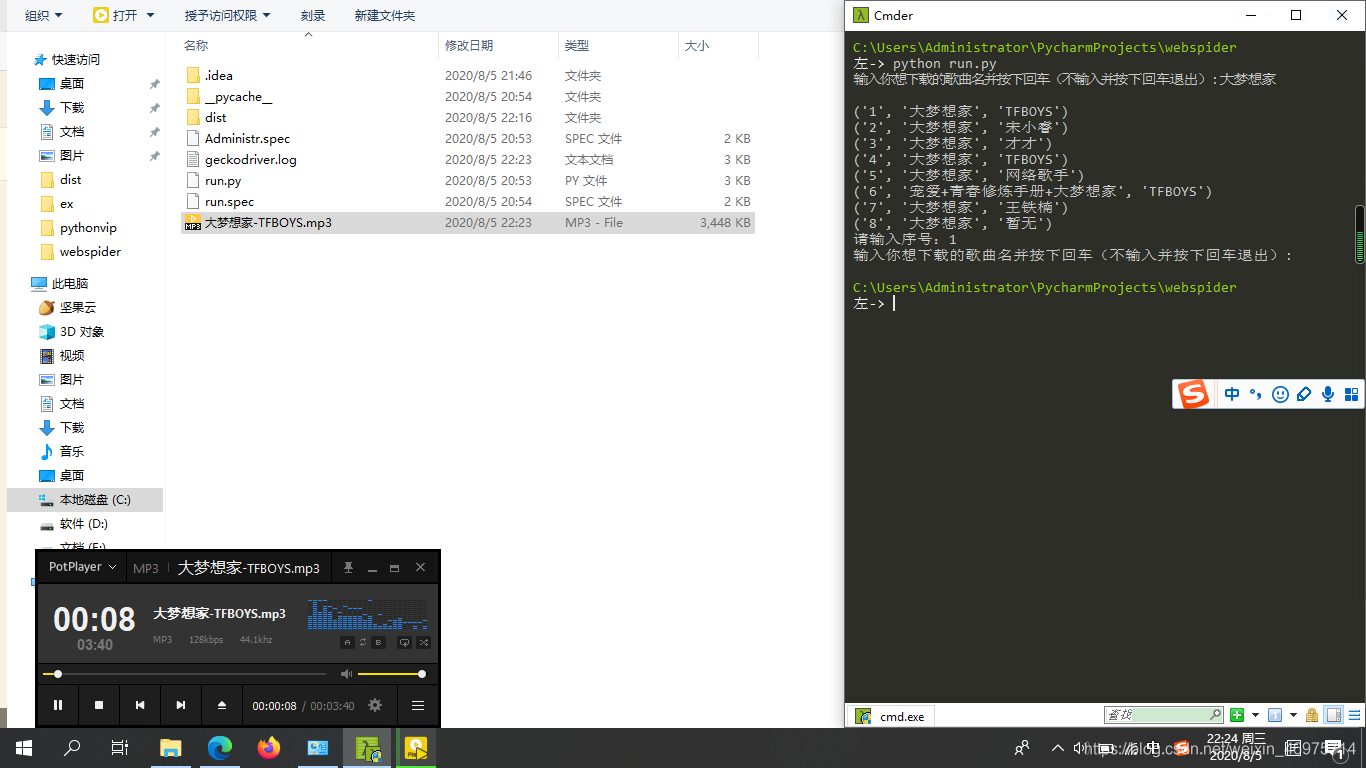
exe文件下载地址:https://www.jianguoyun.com/p/DcMuR8YQs7rYCBjy1rED
-小左1120
这个程序费了我2天时间,求求你们点个赞,关个注呗
2年后的补充:
2022/10/4
大家好!版本已经失效了,我学c++,python忘完了,不过壳子能用。全新代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
|
from selenium import webdriver
import time,re,requests
while True:
name = input("输入你想下载的歌曲名并按下回车(不输入并按下回车退出):")
if (name==''):
break
else:
url = "https://music.liuzhijin.cn/?name=" + name + "&type=netease"
def geturl(url):
options = webdriver.FirefoxOptions()
options.add_argument('-headless')
browser = webdriver.Firefox(options=options)
browser.get(url)
time.sleep(3)
while True:
try:
browser.find_element_by_xpath("/html/body/section/div[1]/div/form[2]/div[4]/div/div[4]").click()
except:
break
temp = browser.page_source
browser.close()
return temp
html = geturl(url)
a111 = '''<li class="aplayer-list-light">
<span class="aplayer-list-cur" style="background: #0e90d2;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>
'''
a11='''<li>
<span class="aplayer-list-cur" style="background: .*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a='''<li>
<span class="aplayer-list-cur" style="background:.*?;"></span>
<span class="aplayer-list-index">(.*?)</span>
<span class="aplayer-list-title">(.*?)</span>
<span class="aplayer-list-author">(.*?)</span>
</li>'''
a1=re.findall(a111,html)
b1 = re.findall(a11,html)
b2=re.findall(a,html)
data = a1+b1+b2
song = 0
for i in data:
print(i)
num = input("请输入序号:")
for i in data:
if (str(i[0])==num):
song = i
url1 = "https://music.liuzhijin.cn/?name=" + song[1]+' - '+song[2] + "&type=netease"
a7='''<span class="am-input-group-btn">
<a id="j-src-btn" class="am-btn am-btn-default" target="_blank" href="(.*?)" download="(.*?)">
<i id="j-src-btn-icon" class="am-icon-download"></i>
</a>
</span>
'''
html1=geturl(url1)
a8 = re.findall(a7,html1)
r = requests.get(a8[0][0])
with open(a8[0][1], "wb") as code:
code.write(r.content)
|
现在网站上酷狗失效了(网站上失效的,网站复原了,代码应该也有效)不过网易云还能用,网易云伺候!
写本文时 selenium版本3.141.0
2023/7/28 更新
现在代码仍可用,目前selenium版本4.10.0,火狐115.0.3 (32 位),geckodriver版本0.33.0放于源码目录下运行,本代码应该不能下载vip曲目,望了解。